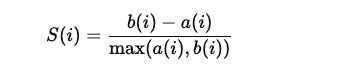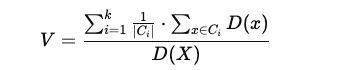Understanding of Attribute types

Know your Data What is data It is set of records, having one or more attributes or features. It is also called collection of data objects. Example of Data Name Income Profession Mother Tongue Native Place Ram 70000 Doctor Bengali Village Shyam 50000 Carpenter Hindi Small Town Mohan 60000 Engineer Hindi Suburban Kabir 90000 Doctor Bengali Metropolitan Fig1. As shown in Fig1, There are four rows and five columns. Record: Each row is called record. There are four records in the example dataset. Features or Attribute: Each column is called feature or attribute of a record in the dataset. There are five attributes for each record in example dataset. Understanding of Data Knowing of data is very important in data science, whether you are doing Data Mining or applying Machine Learning Techniques on data. To understand the data you have to understand each attribute of a record. The following properties of numbers are typically used to describe attributes. Distinctne...