Density Based clustering evaluation with DCV algorithm
Density-Based Cluster Validity (Dcv):
- It evaluates clusters produced by density based clustering algorithms such as DBSCAN and HDBSCAN.
- The fundamental idea of Dcv is to compare the density inside clusters and the density outside the clusters (overall dataset).
- Cluster Density:
- For each cluster Ci, the intra-cluster density D(Ci) is computed by averaging the pairwise distances between all points within the cluster. This gives a measure of how tightly packed the points in the cluster are.
- Overall Dataset Density:
- The overall dataset density D(X) is computed by looking at the pairwise distances between all points in the dataset, both within and outside of clusters. This acts as a baseline density for comparison.
- Validity Measure:
- The Dcv index V is computed by comparing the intra-cluster densities to the overall dataset density:
- For each cluster Ci, the intra-cluster density D(Ci) is computed by averaging the pairwise distances between all points within the cluster. This gives a measure of how tightly packed the points in the cluster are.
- The overall dataset density D(X) is computed by looking at the pairwise distances between all points in the dataset, both within and outside of clusters. This acts as a baseline density for comparison.
- The Dcv index V is computed by comparing the intra-cluster densities to the overall dataset density:
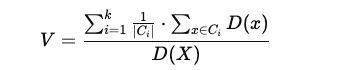
∣Ci∣ is the number of points in cluster Ci.
D(x) is the density for each point in cluster Ci.
D(X) is the overall dataset density.
The Dcv score can be interpreted as the average intra-cluster density divided by the overall dataset density.
A high Dcv score indicates that the points within clusters are much denser than the overall dataset, which suggests good clustering.
A low Dcv score means the clusters are not much denser than the overall dataset, indicating poor clustering or that the clusters are not well-separated.
Pros of Dcv:
Works well with non-convex clusters.
Can handle varying densities within the dataset.
Evaluates noise and outliers effectively.
Cons of Dcv:
Computationally expensive, especially when calculating pairwise distances for large datasets.
Not as widely supported in standard clustering libraries.
Sensitive to parameters like ϵ\epsilonϵ and min_samples in DBSCAN/HDBSCAN, meaning careful tuning is needed.


Comments
Post a Comment